Action as Language :
Fine-Tuning VLMs into VLAs Without Catastrophic Forgetting


We introduce VLM2VLA, a VLA model training paradigm that represents low-level robot actions in natural language to better align the robot fine-tuning data with the base VLM's representation space. This alignment makes it possible to train VLAs solely with Low-Rank Adaptation (LoRA). Through extensive experimentation, we show VLM2VLA yields a policy with strong VQA performance and zero-shot generalization to new scenarios.
Abstract
Fine-tuning vision-language models (VLMs) on robot teleoperation data to create vision-language-action (VLA) models is a promising paradigm for training generalist policies, but it suffers from a fundamental tradeoff: learning to produce actions often diminishes the VLM's foundational reasoning and multimodal understanding, hindering generalization to novel scenarios, instruction following, and semantic understanding.
We argue that this catastrophic forgetting is due to a distribution mismatch between the VLM's internet-scale pretraining corpus and the robotics fine-tuning data.
Inspired by this observation, we introduce VLM2VLA: a VLA training paradigm that first resolves this mismatch at the data level by representing low-level actions with natural language.
This alignment makes it possible to train VLAs solely with Low-Rank Adaptation (LoRA), thereby minimally modifying the VLM backbone and averting catastrophic forgetting.
As a result, the VLM can be fine-tuned on robot teleoperation data without fundamentally altering the underlying architecture and without expensive co-training on internet-scale VLM datasets.
Through extensive Visual Question Answering (VQA) studies and over 800 real-world robotics experiments, we demonstrate that VLM2VLA preserves the VLM's core capabilities, enabling zero-shot generalization to novel tasks that require open-world semantic reasoning and multilingual instruction following.
Representing Actions as Natural Language
The current paradigm of fundamentally modifying the VLM's architecture, tokenization vocabulary, or a combination thereof, coupled with full parameter fine-tuning on robot imitation learning data, introduces a crucial yet often overlooked trade-off when training VLAs: catastrophic forgetting, where the VLM backbone loses its general-purpose world knowledge acquired during pretraining. Our key insight is that while parameter-efficient methods like Low-Rank Adaptation (LoRA) can avert catastrophic forgetting, their effectiveness relies on the fine-tuning data being sufficiently close to the model's pretrained representations. We therefore propose resolving this representational mismatch at the data level. Our data-centric approach re-represents robot actions as natural language descriptions, thereby aligning the VLA fine-tuning data directly with the VLM's pretrained representation space. This alignment enables LoRA to effectively adapt the VLM for robotic control without significantly perturbing its pretrained weights.
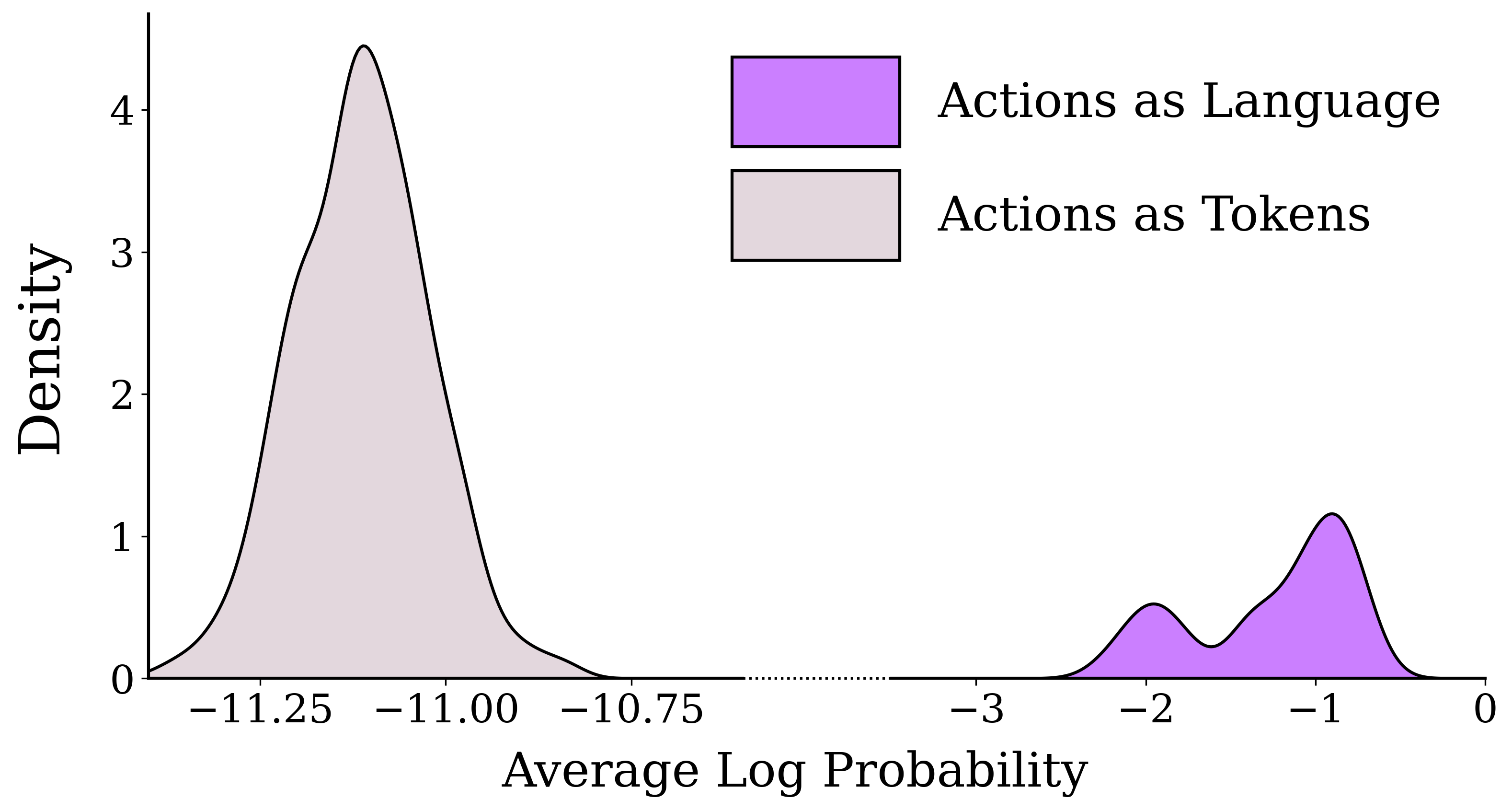
Distribution of action probabilities under Gemma-3-12B-IT before fine-tuning on robot teleoperation data. The model assigns significantly higher log-probabilities to actions represented as language compared to those defined by explicit tokenization modifications, e.g., least likely token assignment.

After fine-tuning, traditional VLA training procedures often overfit to the robot training data, sacrificing their original reasoning capabilities for low-level action prediction (center). In contrast, VLM2VLA preserves the world understanding of the pretrained VLM (left), allowing the model to reason about potential safety risks instead of just motor commands.
Real Robot Experiments
We showcase our model's capabilities on numerous manipulation tasks, some requiring multilingual understanding, object generalization, and following complex, open-vocabulary instructions. We contrast our method to two state-of-the-art VLAs: OpenVLA and Embodied Chain of Thought (ECoT), as well as a token-based ablation of our method (VLMVLA-AT). Videos of VLM2VLA are shown below.
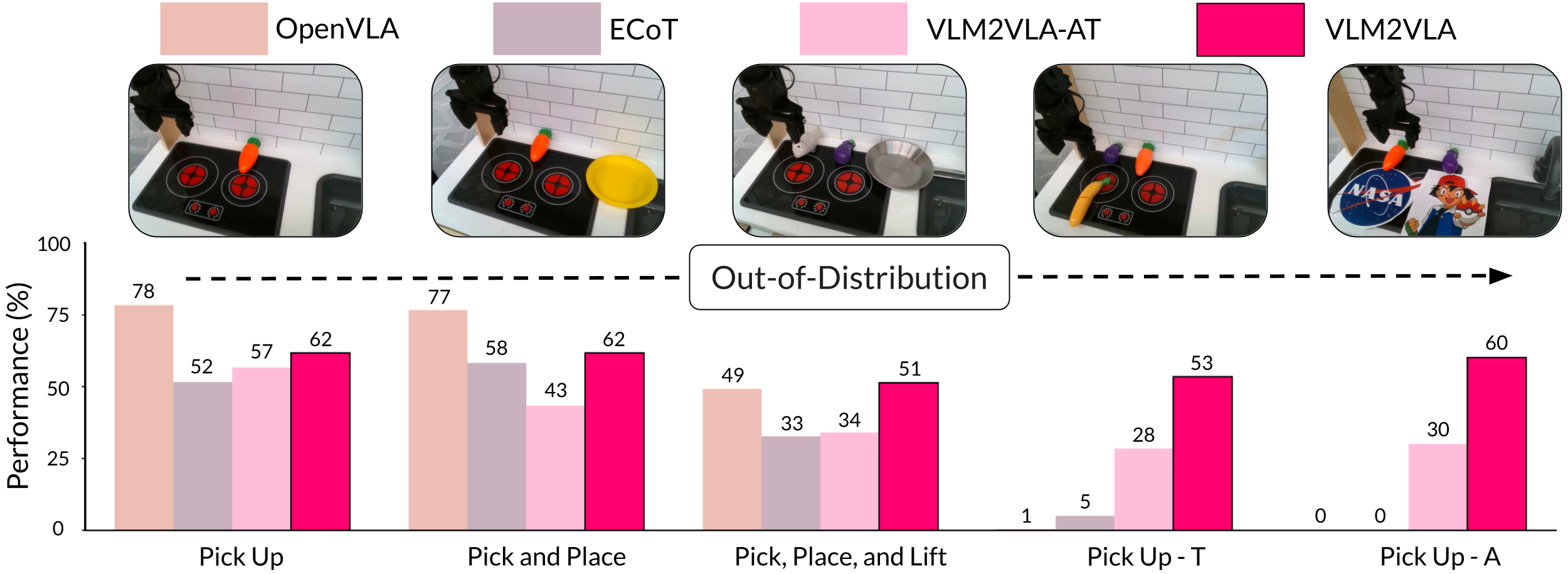
Comparative evaluation of VLA performance on in-distribution (ID) and out-of-distribution (OOD) robotic manipulation tasks. VLM2VLA maintains high success rates on OOD tasks, highlighting its superior generalization capabilities. Embodied Chain of Thought (ECoT), VLM2VLA, and VLM2VLA-AT were fine-tuned on the Bridgev2 dataset, whereas OpenVLA was fine-tuned on the Open-X-Embodiment dataset.
Multimodal Understanding Evaluation
Comparison of VLMs and VLAs across multimodal understanding benchmarks. Our method preserves strong performance across diverse multimodal understanding tasks while maintaining robotic capabilities. The best and second best results for each benchmark are shown in bold and underlined, respectively.
| Method | #Params | MMMU | MMStar | MME | OCRBench | MMB-en | MMB-cn | TextVQA | DocVQA | InfoVQA | AI2D | ChartQA | RealWorldQA |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Prismatic VLM Family | |||||||||||||
| Prismatic VLM | 7b | 35.0 | 38.8 | 1456.6 | 32.0 | 66.2 | 55.7 | 42.5 | 17.5 | 19.7 | 54.6 | 16.7 | 30.8 |
| OpenVLA | 7b | 26.3 | 0 | 0 | 0 | 0 | 43.0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ECoT | 7b | 26.6 | 0 | 0 | 0.01 | 3.7 | 4.1 | 0 | 0 | 0 | 0 | 0 | 25.6 |
| Gemma-3 Family | |||||||||||||
| Gemma-3-4B-IT | 4b | 39.3 | 37.1 | 1205.8 | 70.2 | 68.6 | 64.3 | 61.5 | 68.8 | 40.9 | 70.5 | 50.3 | 44.0 |
| Gemma-3-12B-IT | 12b | 46.0 | 46.3 | 1182.3 | 75.0 | 76.9 | 74.7 | 68.9 | 80.6 | 50.4 | 78.5 | 55.1 | 50.6 |
| VLM2VLA-AT | 12b | 45.9 | 45.2 | 1082.2 | 65.5 | 70.9 | 66.8 | 64.2 | 74.6 | 44.8 | 74.1 | 41.8 | 44.5 |
| VLM2VLA (Ours) | 12b | 42.7 | 48.0 | 1391.7 | 63.9 | 68.5 | 67.6 | 64.9 | 78.4 | 46.2 | 74.0 | 58.3 | 43.3 |
| Open-Source Co-Trained VLAs | |||||||||||||
| MolmoAct | 7b | 28.4 | 1.2 | 1224.5 | 52.7 | 55.1 | 46.3 | 57.5 | 58.7 | 41.9 | 2.0 | 55.9 | 8.6 |
| π0.5 | 3b | 24.0 | 21.7 | 1061.9 | 6.8 | 6.8 | 0.3 | 10.0 | 4.6 | 7.7 | 27.0 | 5.1 | 2.7 |
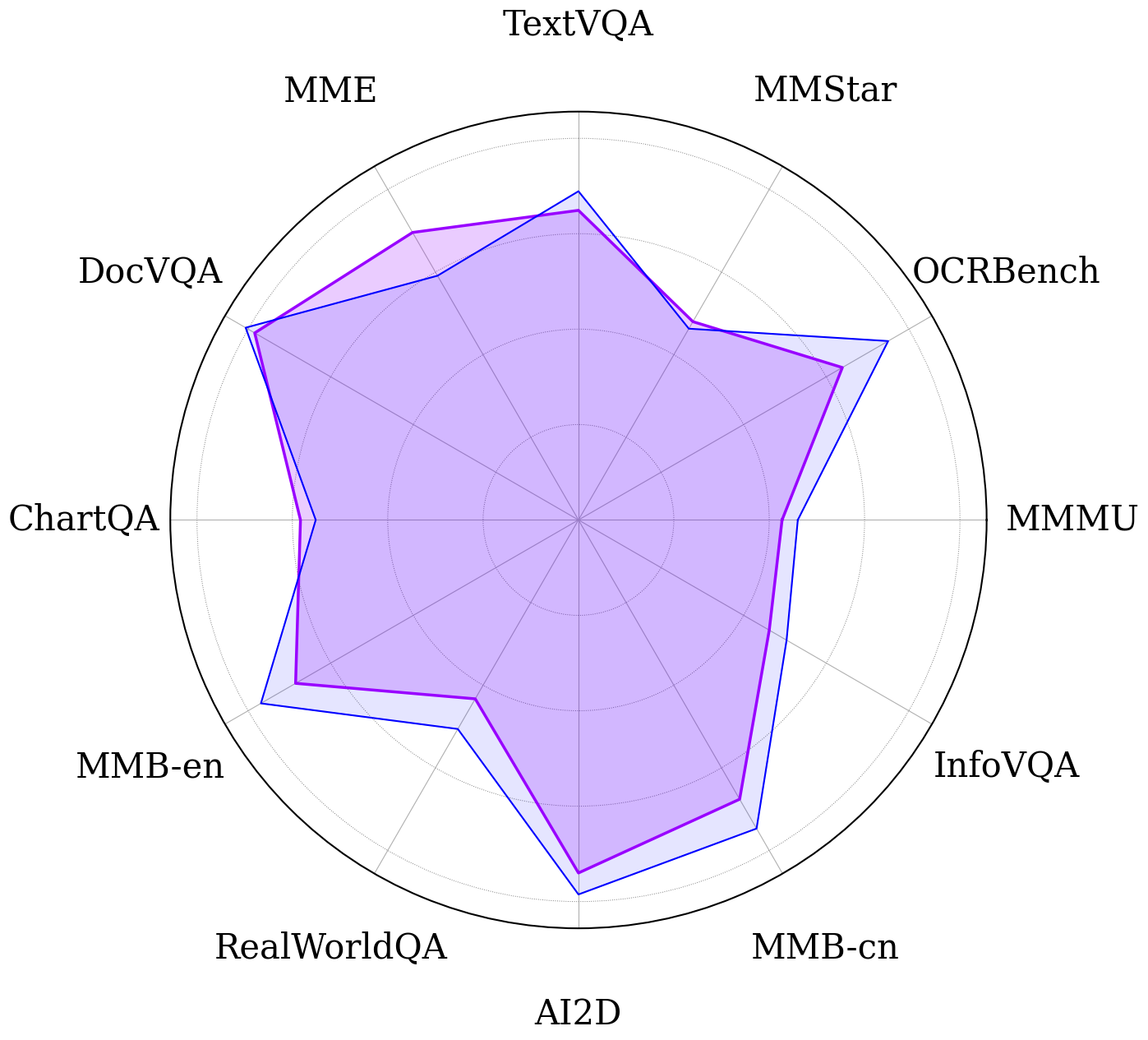
Qualitative examples of VQA performance. Blue is Gemma-3-12B-IT, purple is VLM2VLA